Entradas etiquetadas ‘motor’
Las etiquetas HTML más raras
24 de marzo de 2009en: Sin categoría
![]() Disponemos de un gran número de etiquetas HTML pero a menudo utilizamos sólo un pequeño porcentaje, no siempre con un "<div>" o con un "<span>" podemos solucionar todos nuestros pequeños problemas de HTML.
Disponemos de un gran número de etiquetas HTML pero a menudo utilizamos sólo un pequeño porcentaje, no siempre con un "<div>" o con un "<span>" podemos solucionar todos nuestros pequeños problemas de HTML.
Vamos a ver 10 etiquetas raras, algunas de estas etiquetas no las conoceréis pero otra seguro que las usais a menudo, personalmente no conocía algunas… <abbr>, <address>, <acronym>.
Las 10 etiquetas más raras
1. <wbr>
Ajuste de línea condicional, es muy desconocida y su nombre es debido a la palabra “word break” o “word wrap”, es muy útil cuando un texto es demasiado largo, esta etiqueta romperá la línea si lo considera necesario y añadirá un salto de línea, evitando el incómodo scroll horizontal.
2. <abbr>
Nos permite mostrar algún texto de manera abreviada, de tal modo que al aplicarle un “title” podremos ver su nombre completo al pasar el ratón por encima.
3. <label>
Debería acompañar a cada uno de los campos de un formulario, son muy útiles de cara a la accesibilidad de los mismos y en el caso de los “checkbox” y “radio buttons” son fundamentales.
4. <ins><del>
Suelen utilizarse juntas y su objetivo es remarcar las posibles revisiones de un texto tachando la palabra a omitir y subrayando la nueva palabra.
5. <address>
Esta etiqueta permite marcar direcciones en el HTML y ademas estilizarlas fácilmente con un simple CSS.
6. <acronym>
Parecida a <abbr>, nos permite definir la palabra/s etiquetada/s al pasar el ratón por encima.
- (3) Comentarios
- Etiquetas: googles, motor, rapido, regalo
Servicios de estadísticas gratuitos
24 de marzo de 2009en: Negocio
 Hay un gran número de servicios o herramientas para medir las estadísticas de tu sitio web, habitualmente lo utilizamos para obtener simplemente el dato de visitantes de nuestros sitios, pero hay otro perfil de usuario que busca datos más detallados sobre los usuarios que visitan nuestro sitio como pueden ser: tiempo medio de permanencia, origen geográfico de las visitas, páginas vistas por usuario, etc…
Hay un gran número de servicios o herramientas para medir las estadísticas de tu sitio web, habitualmente lo utilizamos para obtener simplemente el dato de visitantes de nuestros sitios, pero hay otro perfil de usuario que busca datos más detallados sobre los usuarios que visitan nuestro sitio como pueden ser: tiempo medio de permanencia, origen geográfico de las visitas, páginas vistas por usuario, etc…
En esta entrada presentamos varias opciones con diferentes características por lo que únicamente deberemos buscar aquellos servicios que mejor encajen con nuestras necesidades.
En este caso sólo vamos a comentar las estadísticas que se realizan con medidores que son utilizados mediante elementos colocados en la página web, todos estos medidores ofrecen un elemento para insertar en nuestra página (código javascript o imagen).
Aclaramos este puntos porque también existen otro tipo de medidores como Webalizer y Analyzer que almacenan en el servidor toda la información de un visitante.
¿Por qué las mediciones de diferentes servicios no coinciden?
A menudo tenemos varios servicios para medir la estadísticas de nuestros sitios web, en la mayoria de los casos se combinan los servicios web anteriormente citados (Analytics, StatCounter, W3Counter) con los servicios del lado del servidor (Webalizer, Analyzer).
Ejemplo: Webalizer vs Analytics
En estos casos, por ejemplo (Webalizer vs Analytics) el problema está en la recepción de la información.
Webalizer recoge la información una vez se le ha enviado al usuario la página desde el servidor mientras que Analytics lo hace por medio de un elemento en el HTML de la página web (código Javascript) por lo que puede fallar por diversos motivos y no contabilizar la visita.
No por ello debemos pensar que el número de visitantes ofrecidos por Webalizer es el más cercano a la realidad ya que a menudo cuenta un gran número de visitas que en realidad no son visitas propiamente dichas sino más bien son peticiones al servidor.
Ejemplo StatCounter vs Analytics
En el caso anterior está clara la diferencia de visitas entre los diferentes servicios, pero… ¿Por qué dos medidores web ofrecen datos diferentes sobre las estadísticas de una misma página web?
En este caso la clave está en ¿Qué considera cada servicio como una visita?, para algunos puede ser dos visitas cuando una misma persona visita una misma página web en un intervalo de 30 minutos, mientras que si otro medidor fija las visitas en intervalos de 60 minutos únicamente contará una visita.
Servicios de estadísticas gratuitos
Google Analytics
Google Analytics es probablemente el más potente tanto en usuarios que lo utilizan como en las propias características del servicio, para poder acceder necesitaremos una cuenta de Google.
Nos permite monitorizar varios sitios webs en la misma cuenta y posee una interfaz amigable, usable y un gran número de potentes características. Para mostrar los datos utiliza la tecnología Flash por lo que podemos interactuar con los gráficos de las visitas.
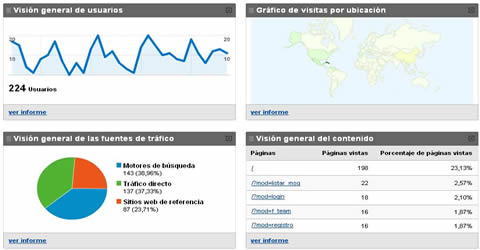
No ofrece estadísticas en tiempo real y el desfase oscila entre las 3 y 4 horas lo que hace que no satisfaga las necesidades de aquellos usuarios que necesitan tener los datos en la menor brevedad de tiempo posible.
StatCounter
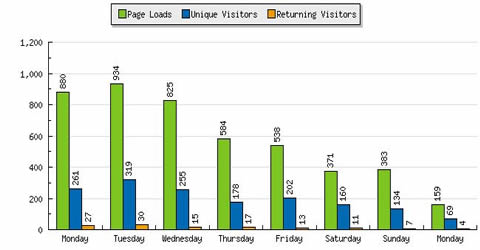
StatCounter nos ofrece los datos en tiempo real lo que permite saber que es lo que está ocurriendo ahora mismo en nuestra web, esto es importante porque podemos saber datos muy interesantes como las palabras clave por la que están accediendo a nuestro sitio a una determinada hora.
El resto de características están muy limitadas en la versión gratuita, cuenta con una versión de pago pero realmente no llega a ofrecer la profundidad de datos de otros medidores de estadísticas web.
- Sin comentarios
- Etiquetas: fracaso, motor, regalo
Buscar en Google Imágenes por colores
23 de marzo de 2009en: Negocio
![]() Google Imágenes permite ahora filtrar las búsquedas por colores, estos filtros se realizan mediante sencillas petiociones (imgcolor=red ó imgcolor=blue,red).
Google Imágenes permite ahora filtrar las búsquedas por colores, estos filtros se realizan mediante sencillas petiociones (imgcolor=red ó imgcolor=blue,red).
Por ejemplo si quisiéramos “buscar coches” accederíamos a la siguiente url:
http://images.google.com/images?q=coches
Sobre esta búsqueda podríamos aplicar el filtro que hemos completado añadiendo la cadena anteriormente citada, por ejemplo busquemos “coches rojos”:
http://images.google.com/images?q=coches&imgcolor=red
Cómo estos filtros se aplican mediante un sencillo parámetro en la URL de la petición de búsqueda es muy fácil hacer un formulario que nos permita hacer búsquedas en Google Imágenes por colores:
- Sin comentarios
- Etiquetas: ie6, motor, rapido
Fácil traductor utilizando PHP
16 de marzo de 2009en: Negocio|Programacion
![]() En este ejemplo vamos a ver como hacer una pequeña aplicación con PHP que nos permita traducir todo tipos de contenidos sin la necesidad de utilizar Ajax, para ello utilizamos Google Ajax Language API, y es que aunque el nombre de la API dice bien claro “Ajax” esta API nos da soluciones para aquellos entornos de desarrollo que no disponen de la posibilidad de utilizar Javascript, por ejemplo como en este caso con PHP o para desarrolladores Flash.
En este ejemplo vamos a ver como hacer una pequeña aplicación con PHP que nos permita traducir todo tipos de contenidos sin la necesidad de utilizar Ajax, para ello utilizamos Google Ajax Language API, y es que aunque el nombre de la API dice bien claro “Ajax” esta API nos da soluciones para aquellos entornos de desarrollo que no disponen de la posibilidad de utilizar Javascript, por ejemplo como en este caso con PHP o para desarrolladores Flash.
En todos los casos el método permitido es GET y el formato de respuesta es JSON, es realmente sencillo de utilizar gracias a esta facilidad que nos ofrece en ambas características. Es muy importante que en este ejemplo pongamos correctamente las cabeceras en las peticiones y del mismo modo necesitaremos utilizar una clave para nuestro dominio (API Key).
Únicamente el ejemplo lo que hará es pasarle a nuestro script PHP alguna palabra o frase y este script en PHP hará una petición que con la ayuda de las funciones de curl nos devolverá las palabras traducidas.
- Sin comentarios
- Etiquetas: gratis, motor, rapido, regalo
Cómo ver las contraseñas almacenadas en Google Chrome
14 de marzo de 2009en: Sin categoría
 Cuando escribes una contraseña en un formulario de cualquiera de los navegadores más populares (Internet Explorer y Firefox) te ofrecen recordarla, si se trata de tu ordenador personal e incluso del ordenador que utilizas en el trabajo lo más probable es que pulses que sí y la contraseña quede almacenada en el navegador.
Cuando escribes una contraseña en un formulario de cualquiera de los navegadores más populares (Internet Explorer y Firefox) te ofrecen recordarla, si se trata de tu ordenador personal e incluso del ordenador que utilizas en el trabajo lo más probable es que pulses que sí y la contraseña quede almacenada en el navegador.
Hasta este momento todo normal… almacenamos nuestras contraseñas en nuestro navegador para recordarlas la próxima vez que tengamos que utilizarlas, el problema lo tenemos si alguien utiliza nuestro ordenador y sabe donde buscar para descubrir nuestras contraseñas.
Descubrir contraseñas con IE, Firefox y Google Chrome
Google Chrome
Google Chrome a pesar de ser el más joven no se libra, también podremos descubrir las contraseñas almacenadas con ChromePass.
La aplicación nos muestra en pantalla una dirección url y el usuario y contraseña con la que se han identificado en ella aparte de la fecha en la que se entró por primera vez.
- (2) Comentarios
- Etiquetas: donacion, motor, reconocimiento, regalo
Agujeros negros en Internet
9 de marzo de 2009en: Sin categoría
![]() Los agujeros negros son regiones del espacio-tiemo a las cuáles ninguna particula material pueden escapar, en Internet también existen agujeros negros y sus efectos son igual de devastadores, en este caso podemos decir que un “agujero negro” en Internet es un sitio web que se traga todos los enlaces entrantes y no devuelve ningún enlace al exterior por lo que infinidad de datos van directamente dirigidos hacia la nada.
Los agujeros negros son regiones del espacio-tiemo a las cuáles ninguna particula material pueden escapar, en Internet también existen agujeros negros y sus efectos son igual de devastadores, en este caso podemos decir que un “agujero negro” en Internet es un sitio web que se traga todos los enlaces entrantes y no devuelve ningún enlace al exterior por lo que infinidad de datos van directamente dirigidos hacia la nada.
Para entenderlo mejor podríamos decir que estos agujeros negros se tragan literalmente el PageRank de las webs que les ofrecen enlaces entrantes, consiguen quedarse el PageRank mediente el uso de la etiqueta rel=”nofollow”.
Wikipedia o Twitter, grandes agujeros negros de Internet
Si hablamos de webs con gran cantidad de tráfico el efecto es muy importante ya que al no enlazar fuera pueden llegar a dominar por completo los resultados de las temáticas en las que mejor posicionan, el caso más claro es la Wikipedia.
Otro caso importante de agujero negro es Twitter que en un principio no utilizaba este tipo de prácticas pero que ya sí que lo hace por lo que poco a poco comienza a posicionar por más y más términos, el caso de la Wikipedia lo puedo llegar a soportar porque al fin y al cabo nos da información de interés aunque llega a ser cansino que aparezca una y otra vez como primer resultado de búsqueda, pero… ¿Qué sentido tiene que Twitter posicione en puestos altos en los términos de búsqueda más populares?, la respuesta es ninguno y probablemente es podríamos decir que en el 90% de los casos puede ser considerado spam ya que la información ofrecida por Twitter poco o nada puede aportarnos en la mayotía de nuestras búsquedas.
Si se trata de una web de escasa influencia no merece la pena no enlazar al exterior.
- (1) Comentario
- Etiquetas: apache, motor, rapido, regalo
Últimas entradas
- 5 herramientas gratis para diseñadores
- Photaki, recursos gráficos low cost para webmasters
- Joaquín Cuenca presentó en el reciente EmTech Europa su nuevo proyecto, Thumbr.it
- Popuz, la red social de los juegos sociales
- Juego de Fútbol Sala
- Discos SSD
- Popuz.com, red social de managers deportivos online
- ¿Cómo Google ha acabado con la larga cola?
- Fantasy Manager, juego de fútbol gratuito
- Cómo de grande es Tuenti si la comparamos con Facebook

Suscripción
POR RSS
POR EMAIL
Recibe los nuevos artículos de TuFunción directamente en tu email