Entradas etiquetadas ‘rapido’
Buscar en Google Imágenes por colores
23 de marzo de 2009en: Negocio
![]() Google Imágenes permite ahora filtrar las búsquedas por colores, estos filtros se realizan mediante sencillas petiociones (imgcolor=red ó imgcolor=blue,red).
Google Imágenes permite ahora filtrar las búsquedas por colores, estos filtros se realizan mediante sencillas petiociones (imgcolor=red ó imgcolor=blue,red).
Por ejemplo si quisiéramos “buscar coches” accederíamos a la siguiente url:
http://images.google.com/images?q=coches
Sobre esta búsqueda podríamos aplicar el filtro que hemos completado añadiendo la cadena anteriormente citada, por ejemplo busquemos “coches rojos”:
http://images.google.com/images?q=coches&imgcolor=red
Cómo estos filtros se aplican mediante un sencillo parámetro en la URL de la petición de búsqueda es muy fácil hacer un formulario que nos permita hacer búsquedas en Google Imágenes por colores:
- Sin comentarios
- Etiquetas: ie6, motor, rapido
Fácil traductor utilizando PHP
16 de marzo de 2009en: Negocio|Programacion
![]() En este ejemplo vamos a ver como hacer una pequeña aplicación con PHP que nos permita traducir todo tipos de contenidos sin la necesidad de utilizar Ajax, para ello utilizamos Google Ajax Language API, y es que aunque el nombre de la API dice bien claro “Ajax” esta API nos da soluciones para aquellos entornos de desarrollo que no disponen de la posibilidad de utilizar Javascript, por ejemplo como en este caso con PHP o para desarrolladores Flash.
En este ejemplo vamos a ver como hacer una pequeña aplicación con PHP que nos permita traducir todo tipos de contenidos sin la necesidad de utilizar Ajax, para ello utilizamos Google Ajax Language API, y es que aunque el nombre de la API dice bien claro “Ajax” esta API nos da soluciones para aquellos entornos de desarrollo que no disponen de la posibilidad de utilizar Javascript, por ejemplo como en este caso con PHP o para desarrolladores Flash.
En todos los casos el método permitido es GET y el formato de respuesta es JSON, es realmente sencillo de utilizar gracias a esta facilidad que nos ofrece en ambas características. Es muy importante que en este ejemplo pongamos correctamente las cabeceras en las peticiones y del mismo modo necesitaremos utilizar una clave para nuestro dominio (API Key).
Únicamente el ejemplo lo que hará es pasarle a nuestro script PHP alguna palabra o frase y este script en PHP hará una petición que con la ayuda de las funciones de curl nos devolverá las palabras traducidas.
- Sin comentarios
- Etiquetas: gratis, motor, rapido, regalo
Agujeros negros en Internet
9 de marzo de 2009en: Sin categoría
![]() Los agujeros negros son regiones del espacio-tiemo a las cuáles ninguna particula material pueden escapar, en Internet también existen agujeros negros y sus efectos son igual de devastadores, en este caso podemos decir que un “agujero negro” en Internet es un sitio web que se traga todos los enlaces entrantes y no devuelve ningún enlace al exterior por lo que infinidad de datos van directamente dirigidos hacia la nada.
Los agujeros negros son regiones del espacio-tiemo a las cuáles ninguna particula material pueden escapar, en Internet también existen agujeros negros y sus efectos son igual de devastadores, en este caso podemos decir que un “agujero negro” en Internet es un sitio web que se traga todos los enlaces entrantes y no devuelve ningún enlace al exterior por lo que infinidad de datos van directamente dirigidos hacia la nada.
Para entenderlo mejor podríamos decir que estos agujeros negros se tragan literalmente el PageRank de las webs que les ofrecen enlaces entrantes, consiguen quedarse el PageRank mediente el uso de la etiqueta rel=”nofollow”.
Wikipedia o Twitter, grandes agujeros negros de Internet
Si hablamos de webs con gran cantidad de tráfico el efecto es muy importante ya que al no enlazar fuera pueden llegar a dominar por completo los resultados de las temáticas en las que mejor posicionan, el caso más claro es la Wikipedia.
Otro caso importante de agujero negro es Twitter que en un principio no utilizaba este tipo de prácticas pero que ya sí que lo hace por lo que poco a poco comienza a posicionar por más y más términos, el caso de la Wikipedia lo puedo llegar a soportar porque al fin y al cabo nos da información de interés aunque llega a ser cansino que aparezca una y otra vez como primer resultado de búsqueda, pero… ¿Qué sentido tiene que Twitter posicione en puestos altos en los términos de búsqueda más populares?, la respuesta es ninguno y probablemente es podríamos decir que en el 90% de los casos puede ser considerado spam ya que la información ofrecida por Twitter poco o nada puede aportarnos en la mayotía de nuestras búsquedas.
Si se trata de una web de escasa influencia no merece la pena no enlazar al exterior.
- (1) Comentario
- Etiquetas: apache, motor, rapido, regalo
Resultados y aspecto de Google en 2001
3 de marzo de 2009en: Negocio
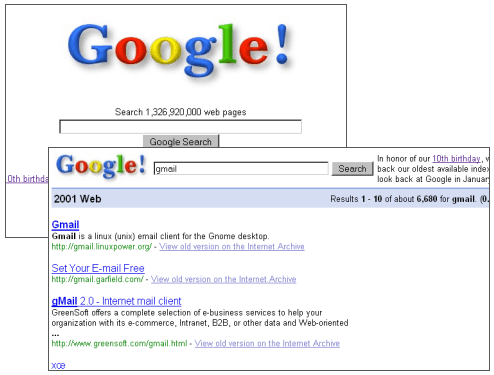
![]() Es un buen momento para viajar en el tiempo y ver cómo lucía el buscador en el año 2001.
Es un buen momento para viajar en el tiempo y ver cómo lucía el buscador en el año 2001.
Cómo se puede ver en la imagen inferior la imagen del buscador se ha mejorado ostensiblemente y su crecimiento ha sido espectacular, en el año 2001 cuando buscábamos en Google lo hacíamos sobre un total de 1,326,920,000 páginas web, hoy en día es difícil encontrar cadenas de búsquedas que no nos devuelvan resultados de calidad.
En 2001 la búsqueda Desarrollo Web devolvía 501,000 resultados, esa misma búsqueda hoy en día devuelve 132,000,000 resultados.
Pero probemos con una búsqueda más generica con la que podamos ver cómo ha crecido el número de resultados de búsquedas con el tiempo.
- Resultados “Política” 2001; 1.050.000 resultados
- Resultados “Política” 2009; 308.000.000 resultados
- (2) Comentarios
- Etiquetas: motor, rapido, regalo
5 etiquetas de HTML olvidadas
25 de febrero de 2009en: Sin categoría
![]() A pesar de disponer de un gran número de etiquetas HTML tendemos a utilizar sólo un pequeño porcentaje porque creemos que con un “<div>” o un “<span>” todo esta solucionado.
A pesar de disponer de un gran número de etiquetas HTML tendemos a utilizar sólo un pequeño porcentaje porque creemos que con un “<div>” o un “<span>” todo esta solucionado.
En SitePoint nos recuerdan 5 etiquetas olvidadas en un gran número de diseños.
<label>
Debería acompañar a cada uno de los campos de un formulario, son muy útiles de cara a la accesibilidad de los mismos y en el caso de los “checkbox” y “radio buttons” son fundamentales.
<fieldset> y <legend>
Agrupa controles en un formulario. Esto permite agrupar temáticamente los controles de un formulario, haciéndolo más fácil de entender y rellenar para el usuario.
<optgroup>
Permite agrupar opciones dentro de un “select”.
<dl>, <dd> y <dt>
<dl> define una lista y una lista está compuesta por términos (<dt>) y descripciones (<dd>). El tipo más común de lista es estructurado por una secuencia de términos y descripciones, donde cada descripción es asociada visualmente a un término.
<q> y <cite>
Contiene una cita o referencia a otro recurso.
- (7) Comentarios
- Etiquetas: motor, rapido, regalo
Gmail está caido
24 de febrero de 2009en: Sin categoría
 Gmail lleva desde aproximadamente las 11:35 de esta mañana caido y por el momento no se ha resuelto, es tal la popularidad de este servicio que la noticia se ha propagado a gran velocidad por Internet.
Gmail lleva desde aproximadamente las 11:35 de esta mañana caido y por el momento no se ha resuelto, es tal la popularidad de este servicio que la noticia se ha propagado a gran velocidad por Internet.
Por ejemplo sólo en Estados Unidos hay ahora mismo 26 millones de usuarios sin acceso al correo electrónico.
¿Te imaginas tu vida sin correo electronico?
- (1) Comentario
- Etiquetas: fotolia, rapido, regalo, windows
Últimas entradas
- 5 herramientas gratis para diseñadores
- Photaki, recursos gráficos low cost para webmasters
- Joaquín Cuenca presentó en el reciente EmTech Europa su nuevo proyecto, Thumbr.it
- Popuz, la red social de los juegos sociales
- Juego de Fútbol Sala
- Discos SSD
- Popuz.com, red social de managers deportivos online
- ¿Cómo Google ha acabado con la larga cola?
- Fantasy Manager, juego de fútbol gratuito
- Cómo de grande es Tuenti si la comparamos con Facebook

Suscripción
POR RSS
POR EMAIL
Recibe los nuevos artículos de TuFunción directamente en tu email