Entradas etiquetadas ‘myisam’
La importancia de conseguir experiencia con grandes bases de datos
9 de diciembre de 2010![]() Personalmente creo haber tenido mucha suerte ya que por una cosa o por otra he participado en varios proyectos que manejan grandes bases de datos, actualmente con Resultados de fútbol y BeSoccer trabajo a diario con un gran volumen de datos que me ayuda a ir cogiendo experiencia a la hora de afrontar el planteamiento de nuevas funcionalidades o mejoras para el proyecto.
Personalmente creo haber tenido mucha suerte ya que por una cosa o por otra he participado en varios proyectos que manejan grandes bases de datos, actualmente con Resultados de fútbol y BeSoccer trabajo a diario con un gran volumen de datos que me ayuda a ir cogiendo experiencia a la hora de afrontar el planteamiento de nuevas funcionalidades o mejoras para el proyecto.
A mi manera de ver lo más importante es llegar a comprender que el problema al final se reduce en conocer perfectamente la tecnología utilizada y cuáles son sus ventajas y desventajas.
Un ejemplo claro está en el uso de MySQL, seguro que alguna vez has escuchado aquello de que MySQL no es recomendado para ser utilizado con grandes tablas. Pero realmente MySQL no es lento con grandes tablas sino que para conseguir un gran rendimiento con MySQL es necesario diseñar la base de datos siendo consciente de lo que puede y no puede hacer el motor de base de datos, tampoco digo con esto que MySQL es mejor que Oracle o PostgreSQL sino que lo que funciona y es eficaz en una no tiene porque serlo en las otras.
Claves en la escalabilidad de MySQL
Veamos algunas de las posibles claves a la hora de mejorar la escalabilidad de una base de datos MySQL:
1. Motor de base de datos
Acertar en la elección del motor de base de datos (MyISAM ó InnoDB)
Cómo comentamos hace unos días hay que ser conscientes de las ventajas y desventajas de cada uno de ellos.
2. Buffers
Cuando no hay memoria suficiente para el manejo de la base de datos notaremos un descenso gradual del rendimiento, la solución sería asegurarnos que tenemos memoria suficiente para el volumen de datos que estamos utilizando.
3. Índices
Es muy sencillo comprender la importancia de los índices, sin un índice, MySql tiene que iniciar una búsqueda por el primer registro y leer toda la tabla para encontrar los registros relevantes.
4. Consultas lentas
Si los anteriores puntos no nos dan la solución probablemente nos tengamos que centrar en la optimización de las consultas, una tarea complicada con la que podemos ahorrar mucho tiempo si conseguimos desde el principio detectar las consultas lentas (slow queries).
Si ninguno de estos puntos soluciona nuestro problema de escalabilidad tendremos que intentarlo con alguno de las siguientes soluciones que son algo más complicadas.
Llegado a este punto en el que necesitamos escalar nuestra base de datos y ninguna de las anteriores soluciones ya nos sirven tendremos que decidir entre:
Escalar verticalmente
Añadir más recursos a un nodo del sistema para mejorar el rendimiento de la base de datos, se trataría de hacer una inversión en hardware.
Pros:
Casi todos los sistemas escalan bien verticalmente.
Fácil de implementar
Fácil de administrar
Contras:
Alto coste del hardware
Escalar horizontalmente
Agregar más nodos al sistema. Se puede escalar horizontalmente con mejoras de hardware (agregar nuevas computadoras al sistema) ó con mejoras de software (Replicación de datos ó “Sharding” por ejemplo)
Pros:
Coste lineal
Contras:
Difícil de implementar
Difícil de administrar
Escalar horizontalmente y verticalmente
Se puede optar por está opción, habitualmente se escala de manera verticalmente mientras el presupuesto lo permita y cuando ya aumentan excesivamente los costos se escala horizontalmente.
Conclusiones
Es relativamente difícil llegar a tener problemas con la base de datos y si lo llegamos a tener será una buena noticia porque significa que nuestro proyecto es lo suficientemente grande como para comenzar a buscar solución a unos problemas que de ser solucionados nos van a permitir seguir creciendo.
Escalar verticalmente es relativamente fácil ya que mientras haya dinero para soportar el coste de hardware no tendremos problemas de escalabilidad, el verdadero reto es conseguir escalar de manera horizontal manteniendo controlado el coste de desarrollo, es realmente complicado porque si llegamos a este punto seguramente careceremos de ejemplos prácticos de cómo hacerlo ya que las estructuras de bases de datos pueden ser muy dispares, por ello no hay ningún método infalible.
- (4) Comentarios
- Etiquetas: base de datos, innodb, myisam, mysql, registro, sharding, web
Datos de seguridad en contraseñas
30 de octubre de 2006en: Estadisticas
 Una serie de gráficas que nos indican el tiempo aproximado requirido por un ordenador o un cluster de ordenadores en adivinar una o varias contraseñas. Cada una de las gráficas muestra un caso hipotético y muestra el tiempo aproximado requerido dependiendo de la clase de máquina que realiza el “ataque”, el método utilizado es la fuerza bruta.
Una serie de gráficas que nos indican el tiempo aproximado requirido por un ordenador o un cluster de ordenadores en adivinar una o varias contraseñas. Cada una de las gráficas muestra un caso hipotético y muestra el tiempo aproximado requerido dependiendo de la clase de máquina que realiza el “ataque”, el método utilizado es la fuerza bruta.
Clases de ataques
A. 10,000 Passwords/seg
Ejemplo: Recuperación de contraseña de MS Office en un Pentium 100
B. 100,000 Passwords/seg
Ejemplo: Recuperación de contraseña Microsoft (Archivos .PWL)en un Pentium 100
C. 1,000,000 Passwords/seg
Ejemplo: Recuperación de contraseña de un archivo comprimido en ZIP o ARJ Pentium 100
D. 10,000,000 Passwords/seg
Ejemplo: Recuperación de cualquiera de las contrasñas anteriores con un PC de Gama Alta (+2Gh)
E. 100,000,000 Passwords/seg
Ejemplo: Recuperación de una contraseña con un cluster de microprocesadores o con multiples Pcs trabajando de manera simultánea.
F. 1,000,000,000 Passwords/seg
Ejemplo: Recuperación de una contraseña utilizando una supercomputadora o una red de ordenadores interconectados a gran escala, por ejemplo sitrubed.net: fundado en 1997 y con un poder de computo equivalente a más de 160000 computadoras PII 266MHz trabajando 24 horas al día, 7 días a la semana, 365 días al año!
- (28) Comentarios
- Etiquetas: innodb, Movil, myisam, reconocimiento, regalo, registro, visual
Google afirma que el primer motor de búsqueda es MSN
14 de septiembre de 2006en: Negocio
 No lo dice ningún medio informativo la fuente de esta información es el propio Google, el debate esta servido, este debate hace unos años lo hubieramos calificado de ridículo por el dominio de MSN frente a Google (Artículo Barrapunto 2003), lo único que debemos de tener claro que en la guerra de los tres principales buscadores de Internet, quizás los mas beneficiados seamos los usuarios ya que normalmente “pelan” para ofrecer el mejor servicio.
No lo dice ningún medio informativo la fuente de esta información es el propio Google, el debate esta servido, este debate hace unos años lo hubieramos calificado de ridículo por el dominio de MSN frente a Google (Artículo Barrapunto 2003), lo único que debemos de tener claro que en la guerra de los tres principales buscadores de Internet, quizás los mas beneficiados seamos los usuarios ya que normalmente “pelan” para ofrecer el mejor servicio.
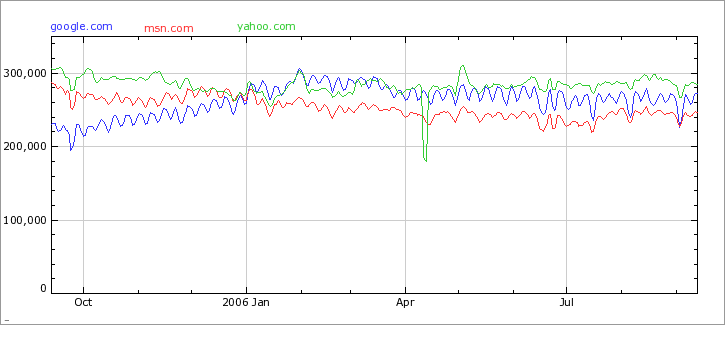
Esta es una comparativa de la evolución de esta “guerra” en el último año:
Últimas entradas
- 5 herramientas gratis para diseñadores
- Photaki, recursos gráficos low cost para webmasters
- Joaquín Cuenca presentó en el reciente EmTech Europa su nuevo proyecto, Thumbr.it
- Popuz, la red social de los juegos sociales
- Juego de Fútbol Sala
- Discos SSD
- Popuz.com, red social de managers deportivos online
- ¿Cómo Google ha acabado con la larga cola?
- Fantasy Manager, juego de fútbol gratuito
- Cómo de grande es Tuenti si la comparamos con Facebook

Suscripción
POR RSS
POR EMAIL
Recibe los nuevos artículos de TuFunción directamente en tu email